It is Infrastructure as Code, not Infrastructure as YAML!
YAML with templating is not Infrastructure as Code. A look at why sysadmins deserve real programming languages, and what tools like PyInfra offer over Ansible and Helm.


Welcome back to our blog, after our summer break!

We did one article per week for 51 weeks (yes, we know, almost a year), and we thought that a pause was necessary, in order to have some inspiration and stories to tell!
So here we are: choosing a topic, and creating a buzz by destroying it, and our target today is the Code in Infrastructure as Code! (Hello Ansible!)

What is Infrastructure as Code (IaC)?
According to Wikipedia:
Infrastructure as code (IaC) is the process of managing and provisioning computer data centers through machine-readable definition file (...)
And that's where the problem is: "machine-readable definition file"!
Stay with me for a few more seconds for another definition: what is code?
In computing, source code, or simply code, is any collection of code, with or without comments, written using a human-readable programming language, usually as plain text.
So here is the question: is that code?
- name: systemd-timescynd config
template:
src: timesyncd.conf.j2
dest: /etc/systemd/timesyncd.conf
notify: restart systemd-timesyncdWhat is it? it's a part of a file, used by Ansible, in order to define/change the NTP server(s), but at the end, it's some YAML.
Same story for this example:
{{- if and .Values.networkPolicy.enabled (or .Values.networkPolicy.egressRules.denyConnectionsToExternal .Values.networkPolicy.egressRules.customRules) }}
apiVersion: {{ include "common.capabilities.networkPolicy.apiVersion" . }}
kind: NetworkPolicy
metadata:
name: {{ printf "%s-egress" (include "common.names.fullname" .) }}
namespace: {{ .Release.Namespace }}
labels: {{- include "common.labels.standard" . | nindent 4 }}
{{- if .Values.commonLabels }}
{{- include "common.tplvalues.render" ( dict "value" .Values.commonLabels "context" $ ) | nindent 4 }}
{{- end }}
{{- if .Values.commonAnnotations }}
annotations: {{- include "common.tplvalues.render" ( dict "value" .Values.commonAnnotations "context" $ ) | nindent 4 }}
{{- end }}
spec:
podSelector:
matchLabels: {{- include "common.labels.matchLabels" . | nindent 6 }}
policyTypes:
- Egress
egress:
{{- if .Values.networkPolicy.egressRules.denyConnectionsToExternal }}
- ports:
- port: 53
protocol: UDP
- port: 53
protocol: TCP
- to:
- namespaceSelector: {}
{{- end }}
{{- if .Values.networkPolicy.egressRules.customRules }}
{{- include "common.tplvalues.render" (dict "value" .Values.networkPolicy.egressRules.customRules "context" $) | nindent 4 }}
{{- end }}
{{- end }}It's a part of the Helm chart by Bitnami to deploy PostgreSQL on Kubernetes!
Why does it look so ugly, like a mix of templating + YAML?
Is that not a paradox that in the computer industry, we are not able to use a real programming language to define what we want to do on an infrastructure? Why do we have to learn this crazy syntax?
Are sysadmin so hard to manage, and teach them some code? I don't think so!
History of tools

In the beginning the Sysadmin created the Infrastructure and the Network.
And the Infrastructure was without form, and void; and darkness was upon the face of the deep. And the Spirit of the Sysadmin moved upon the face of the servers. And the Sysadmin said, Let there be light: and there was no light! There was Puppet! Puppet was very different from the original tool: it was written using Ruby, but was using it's own declarative language, which could be tricky, especially if you wanted to integrate with other tools through an API! Then a lot of tools followed, mostly following the same pattern: Having a pull method, and being mostly declarative.
Puppet was not the first
Pull Method? Declarative?
yes, yes, yes, I know, I'm running hither and thither, so let's go back a bit:
Pull vs Push

There are two methods of IaC: push and pull. The main difference is the manner in which the servers are told how to be configured. In the pull method, the server to be configured will pull its configuration from the controlling server. In the push method, the controlling server pushes the configuration to the destination system.
Each system has its pros and cons!
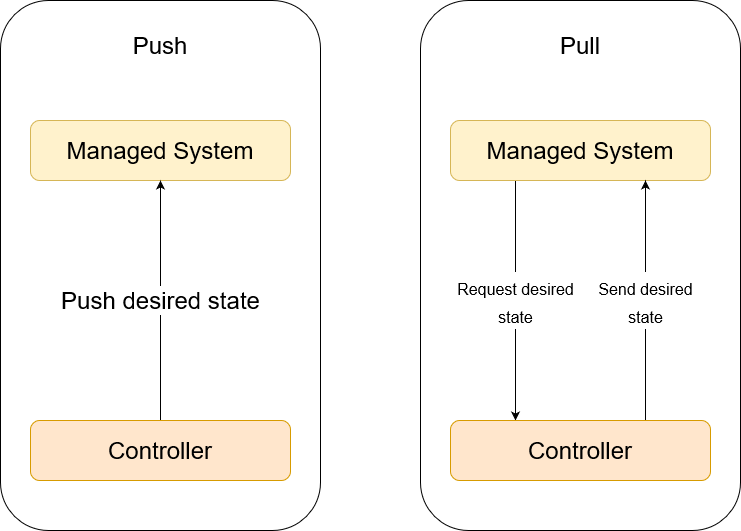
Advantages of Push based Configuration Management
- Control over the entire system: Since the main server (where you store the configuration information) pushes the configuration to the nodes, you have more control over what nodes need to be configured, the actions are more synchronous and error handling becomes much easier since you can immediately see & correct the issues.
- Simpler to use: Push configuration management tools, like Ansible, are generally much easier to setup and get started. Also, since nodes do not pull any information from the main server, development is more straight forward as you can easily test your scripts without worrying about any node picking it up accidentally or changing any settings on the agents.
Advantages of Pull based Configuration Management
- Easier to bootstrap new nodes: As soon as a node is ready, agent/client that runs on the node can start pulling configuration from the main server. This means that a new machine configured automatically, when the server is ready to be configured (unlike push method where you have to check if the node is ready to be configured).
- Easier scalability: Since the nodes can be bootstrapped automatically and independent of other nodes, it means that scaling such a configuration is much easier.
Declarative vs Imperative
It's very simple:
- Declarative: Defining What! You specify the name and properties of the infrastructure resources you wish to provision, and then the tool figures out how to achieve that end result. This paradigm is massibely used by Terraform, Puppet, Ansible, Salt, and CloudFormation (and some others).
- Imperative: Defining How! You specify a list of steps the tool should follow to provision a new resource. Chef is a popular imperative IaC tool, and both Ansible and Salt have some support for imperative programming as well.
Nowadays
From a very large study of the industry (based on my twitter timeline, yep), I was able to identify the tools widely used in the industry!

- To manage VMs and Servers, Ansible (with AWX) , grab the lion's share!
- To manage infrastructure, Terraform is winning!
- Helm is the goto tool to manage applications and application states from within a Kubernetes cluster.
And today, I'm going to send Ansible to hell! (The others are coming, no worries!)

Ansible
Don't get me wrong: we are using Ansible for years, and it's a nice tool, but I was getting a bit angry about it for multiple reasons:
- Writing custom inventories was complicated!
- Managing the state during an execution could be tricky!
- Scaling to thousands of servers can be complicated!
We need to understand how Ansible is working:
- Ansible load an inventory containing information about the servers to manage and the associated data/facts
- Ansible load the playbooks, containing a set of roles and define which roles to execute on which server, and create the associated Python code
- Ansible connect to the server, transfer the code, then execute it (Python required on the Managed System)
Let me give you an example: let's say that you want to setup Zero Tier on every server that you manage. On Ansible, the recommendation is going to be to use a role from Ansible Galaxy and wait, there is one, a bit old, but let's have a look on out to register a node on Zero Tier One:
---
- block:
- name: Authorize new members to network
uri:
url: "{{ zerotier_api_url }}/api/network/{{ zerotier_network_id }}/member/{{ ansible_local['zerotier']['node_id'] }}"
method: POST
headers:
Authorization: bearer {{ zerotier_api_accesstoken }}
body:
hidden: false
config:
authorized: "{{ zerotier_authorize_member }}"
body_format: json
register: auth_apiresult
delegate_to: "{{ zerotier_api_delegate }}"
when:
- ansible_local['zerotier']['networks'][zerotier_network_id] is not defined or
ansible_local['zerotier']['networks'][zerotier_network_id]['status'] != 'OK'
- name: Configure members in network
uri:
url: "{{ zerotier_api_url }}/api/network/{{ zerotier_network_id }}/member/{{ ansible_local['zerotier']['node_id'] }}"
method: POST
headers:
Authorization: bearer {{ zerotier_api_accesstoken }}
body:
name: "{{ zerotier_member_register_short_hostname | ternary(inventory_hostname_short, inventory_hostname) }}"
description: "{{ zerotier_member_description | default() }}"
config:
ipAssignments: "{{ zerotier_member_ip_assignments | default([]) | list }}"
body_format: json
register: conf_apiresult
delegate_to: "{{ zerotier_api_delegate }}"
when:
- not ansible_check_mode
tags:
- configuration
become: falseAnd that's the perfect example of what I call over-simplifying something: they wanted to make everybody feel that they can deploy their infrastructure without code, but the complexity of this code is without limit!
Our savior: PyInfra
Ansible and PyInfra are very similar in a lot of ways:
- Python: both tools are developed in Python!
- Agentless: even if PyInfra is a bit better than Ansible, as PyInfra can natively interact with subprocesses and docker containers, without the need to ssh into the container (pure Push)
- Instant Debugging: one of the pleasure of both, you can debug in real time your code
- Two stage process: you can dry run!
- Declarative!
But PyInfra has something more amazing: Everything is Python! Your Inventory, your roles, everything!
Which means that the example from Ansible could be translated into PyInfra as:
import requests
from pyinfra.operations import apt, python, server
# Assumes the repo is configured/apt is updated
apt.packages(
name='Install ZeroTier',
packages=['zerotier-one'],
)
def authorize_server(state, host):
# Run a command on the server and collect status, stderr and stdout
status, stdout, stderr = host.run_shell_command('cat /var/lib/zerotier-one/identity.public')
assert status is True # ensure the command executed OK
# First line of output is the identity
server_id = stdout[0]
# Authorize via the ZeroTier API
response = requests.post('https://my.zerotier.com/.../{0}'.format(server_id))
response.raise_for_status()
python.call(
name='Authorize the server on ZeroTier',
function=authorize_server,
)
server.shell(
name='Execute some shell',
commands=['echo "back to other operations!"'],
)As you can see, instead of using a weird syntax to do a basic curl, we can directly use Requests!
Which means that you can completely interact with your existing code base, integrate with a custom inventory, without fighting with tags, groups as you define by yourself how to build it!
import requests
def get_servers():
db = []
web = []
servers = requests.get('inventory.mycompany.net/api/v1/app_servers').json()
for server in servers:
if server['group'] == 'db':
db.append(server['hostname'])
elif server['group'] == 'web':
web.append(server['hostname'])
return db, web
db_servers, web_servers = get_servers()Another example:
#Ansible
- name: Run the equivalent of "pacman -Sy" as a separate step
community.general.pacman:
update_cache: true
- name: Run the equivalent of "pacman -Su" as a separate step
community.general.pacman:
upgrade: true
#PyInfra
pacman.update()
pacman.upgrade()
Conclusion
You can now understand why we are slowly moving out of Ansible and going into PyInfra! We want to gain the ability to really embrace the Dev inside the Ops department of Kalvad, and we would highly recommend you to test it, especially if you are an Ansible Fan!
If you have a problem and no one else can help. Maybe you can hire the Kalvad-Team.
Stuck Templating YAML?
We build infrastructure automation in actual code: Python with PyInfra, typed pipelines, and tooling your engineers can test and refactor. If your Ansible playbooks have grown into unreadable Jinja and your Helm charts need a debugger, we can help you migrate to something your team can reason about. We do this for fintech, government, and PCI-DSS environments. Let's rebuild your automation in code.