SLA and SLO fundamentals
A practical breakdown of SLA and SLO fundamentals, covering time-based and aggregate-based metrics, downtime budgets, and how to set realistic availability objectives.


SLA aka Service-Level Agreement is an agreement you make with your clients/users, which is a measured metric that can be time-based or aggregate-based.
SLA time-based
We can calculate the tolerable duration of downtime to reach a given number of nines of availability, using the following formula:

For example, a web application with an availability of 99.95% can be down for up to 4.38 hours max in a year.
The following table explains the maximum duration of tolerated downtime per year/month/week/day/hour.
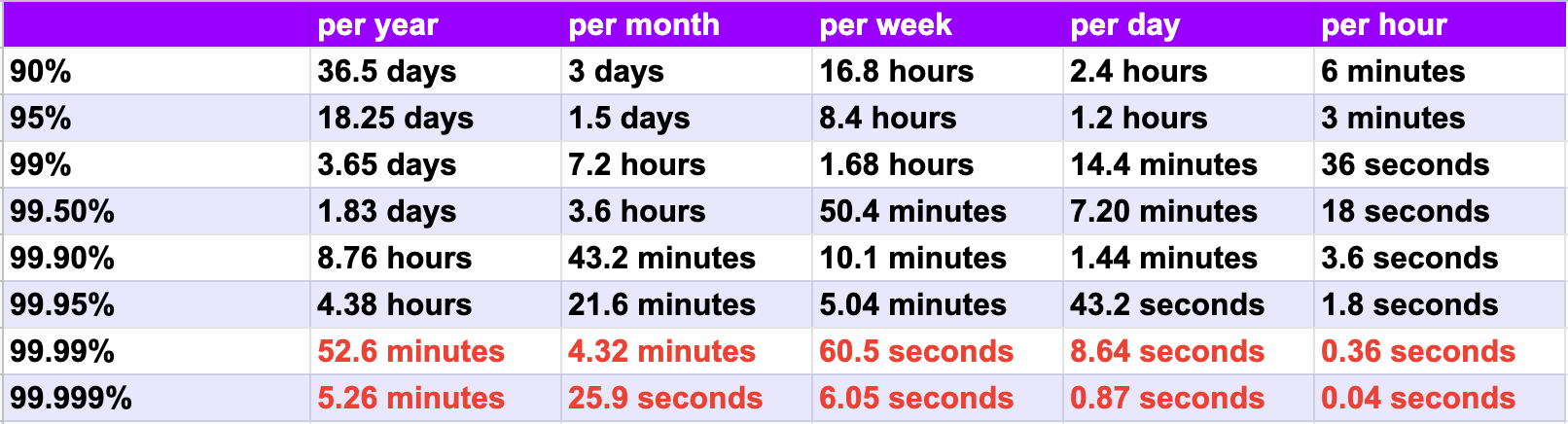
SLA Aggregate-based
Let's imagine a Backend with an API, that serves 250M requests per day, and an SLA Aggregate-based of 99.99% which cannot exceed more than 25k errors per day.

Note that an error is counted if it's an internal server error HTTP 5XX
What is SLO?
SLO aka Service-Level Objective is an SLA agreement that defines the expectations and goals that the company should achieve during a defined period of time.
Example:
Imagine a company with a current Uptime-Based SLA is 95% which means they have a tolerated maximum of 1.5days of downtime per month. (Which is very bad)
We will define our next objectives so the SLA should meet 99%.
For that, we have to take several actions, here are some examples:
- Review the hardware infrastructure
- Add preventive monitoring
- Find the root causes of the downtimes
- Review the network configurations
- Review for any single point of failure
Serious About Your Uptime Numbers?
We design and operate infrastructure where SLAs and SLOs are real engineering targets, not marketing copy. That means monitoring, error budgets, redundancy, and architecture reviews that remove single points of failure. We do this for fintech, government, and PCI-DSS workloads where downtime is measured in money and trust. Let's review your uptime targets.