IPFS in-depth(Myths and Misunderstandings)


First of all, What is IPFS?
The Interplanetary File System (IPFS) is a bundle of subprotocols and a project-driven by Protocol Labs, IPFS aims to improve the web’s efficiency and to make the web more decentralized and resilient.
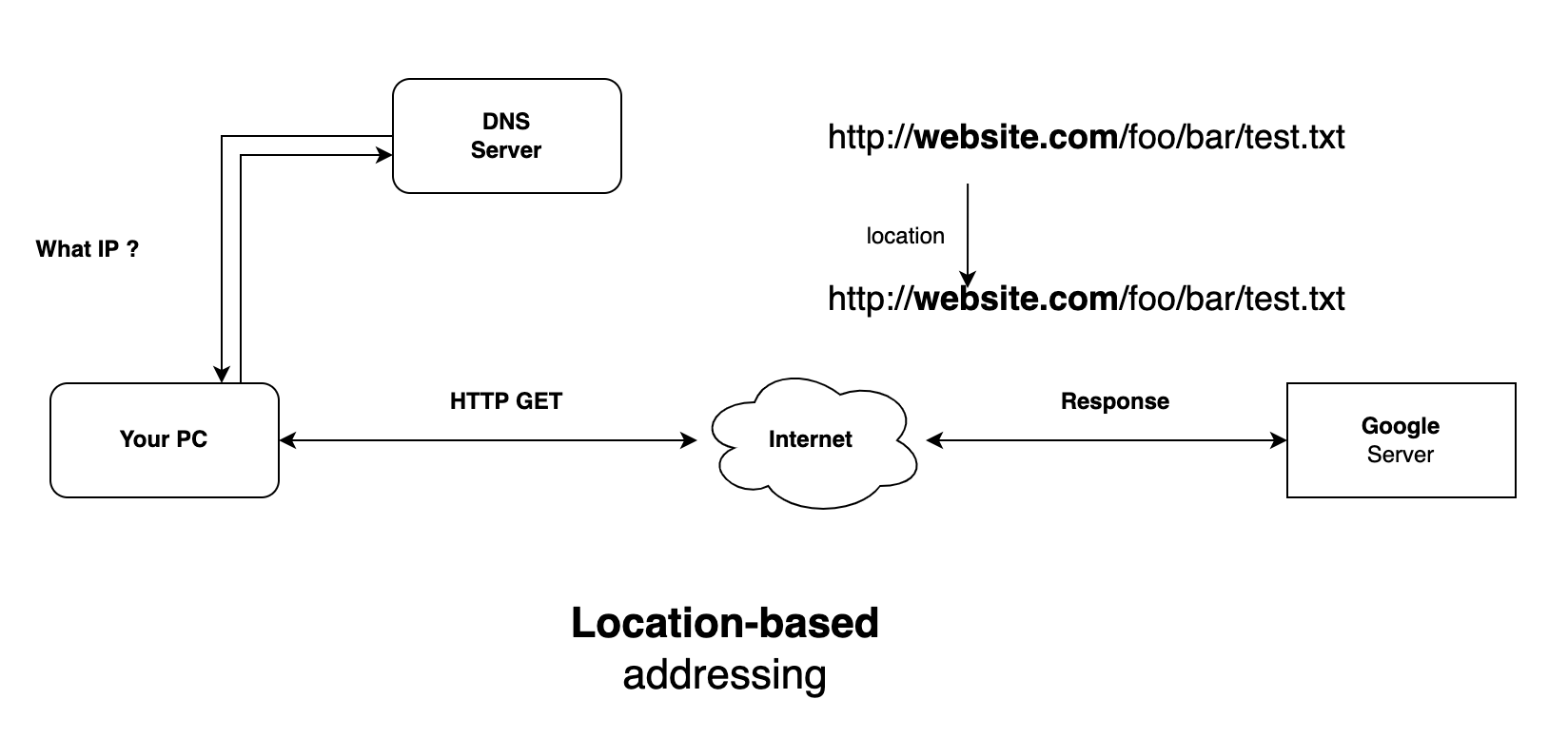
IPFS uses content-based addressing, where content is not addressed via a location but via its content. IPFS stores and addresses data with its deduplication properties, allowing efficient storage of data. It also can be used as a storage service complementing blockchains, enabling different applications on top of IPFS.
Why is it called Interplanetary File Systems? What was the reason behind its creation?

IPFS Originally was created to allow access to files from anywhere — whether it be Mars or any other planet
Alright, so communicating from Mars to Earth is quite difficult, and time-taxing, requesting a Wikipedia page could take up to 48 minutes, which is very time-consuming. (Source)
So this was the first reason behind creating IPFS in order to bridge the gap between the planets due to its distributed storage system.
For example, if a colleague had already requested the Wiki page Mars, you could download it from them easily, just as fast as you would on Earth.
First, we need to understand a few concepts :
1/ Centralized vs Decentralized Networks

2/ Location-Base Addressing
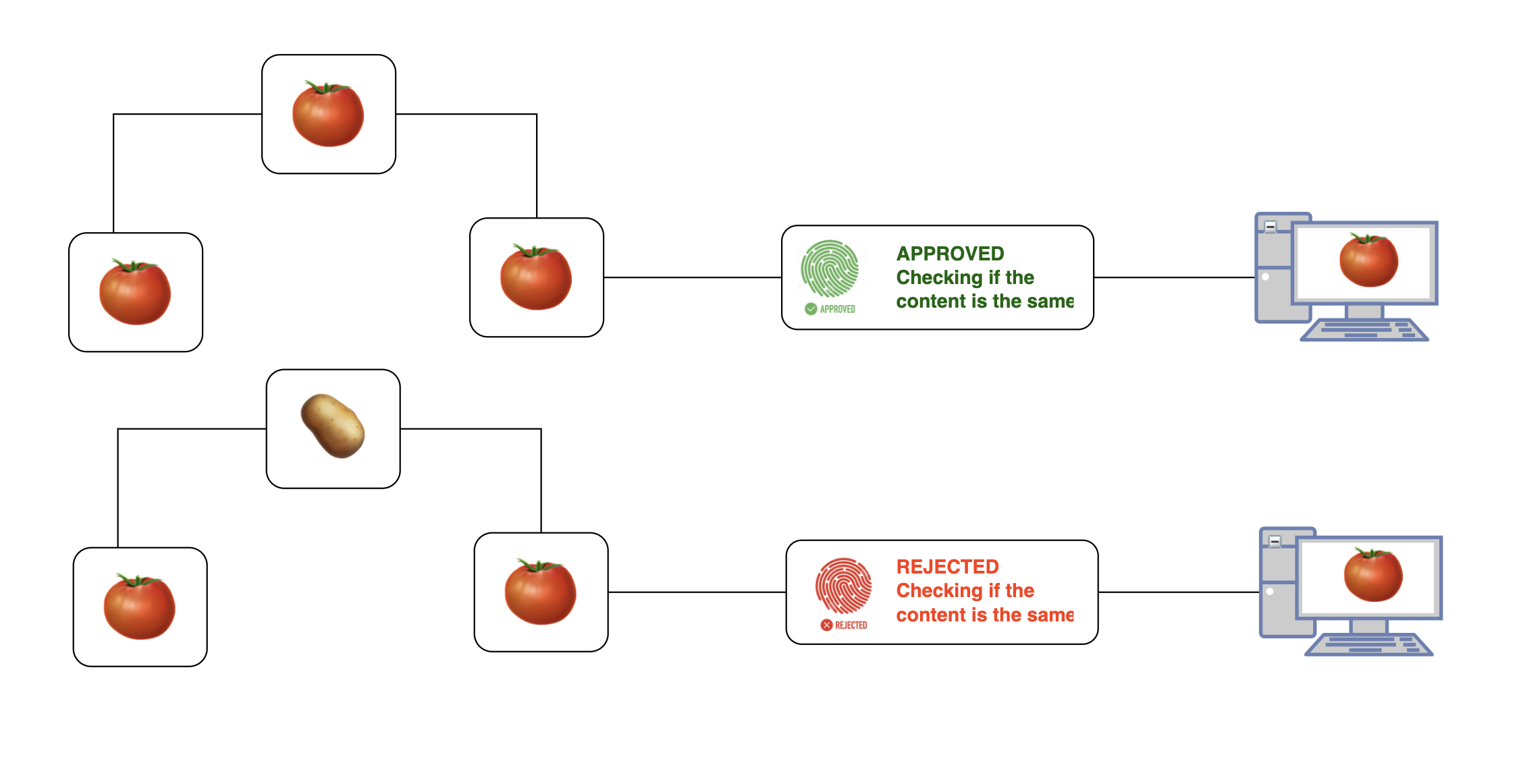
3/ Content-Base Addressing:
How does IPFS work? How exactly do you access content on IPFS?
IPFS is a peer-to-peer network for storing content on a distributed file system.
A set of computers/servers called nodes that store and relay content using a common addressing system.
IPFS nodes communicate via the Internet using a Peer-to-Peer (P2P) architecture, preventing one node from becoming a single point of failure.
libp2p is a modular system of protocols, specifications, and libraries that enable the development of peer-to-peer network applications - libp2p documentation.
That’s exactly what four IPFS nodes need to connect to the IPFS network.
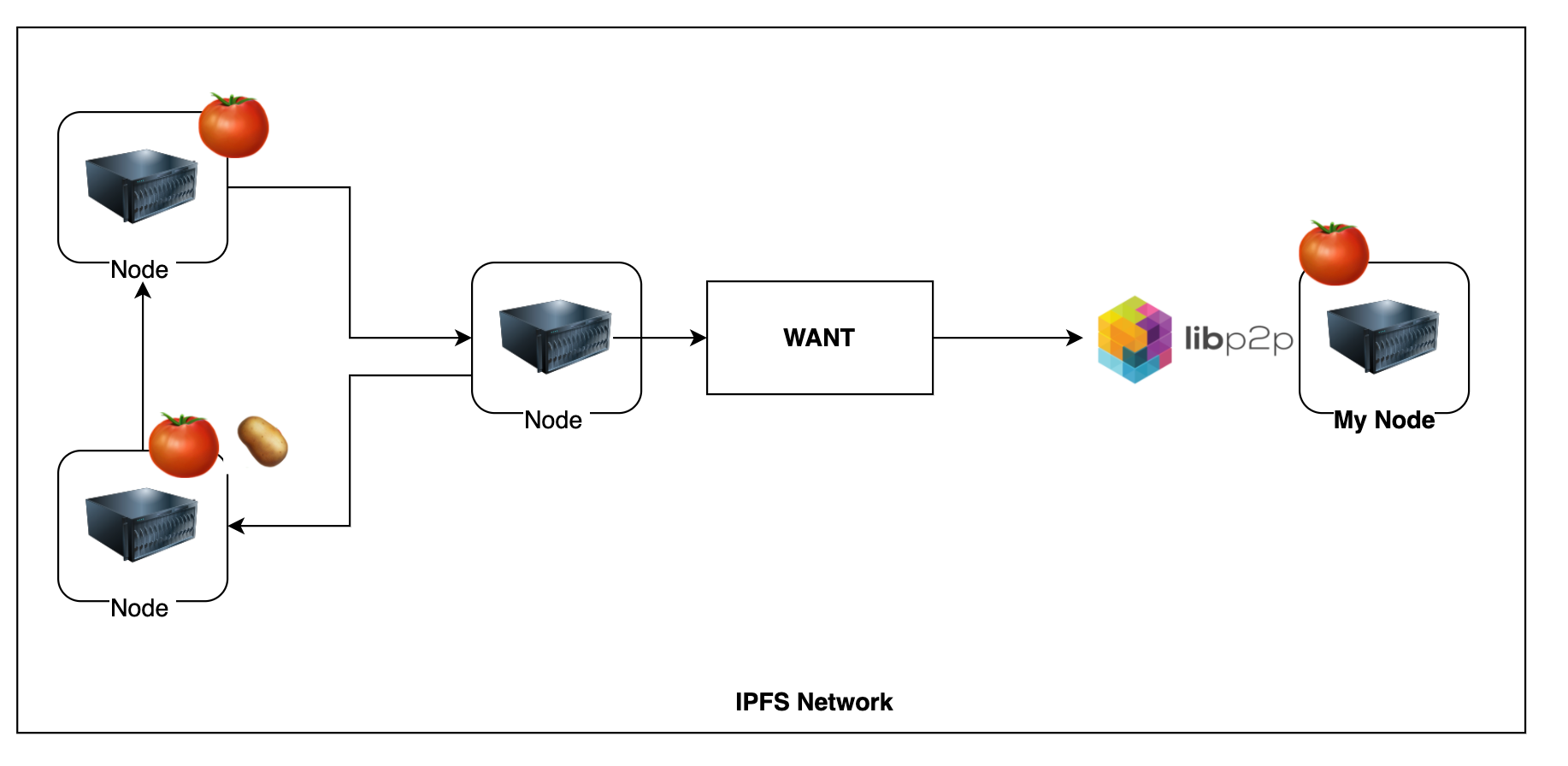
Any node that we maintain a connection with is a peer.
- Any peer node can ask their peers, they want a tomato 🍅 content.
- so, If you do have it, you will give 🍅 to them.
- Else you can give some metadata about the network to help them find another peer who might have it.
- Note that each node chooses the resources they want to keep and store.
- Example: 🍅 will be available on different peers nodes who dedicated resources to store it.
- A 🥔 exists less in the network. so, only a few nodes will provide it.
Introducing IPFS Gateway
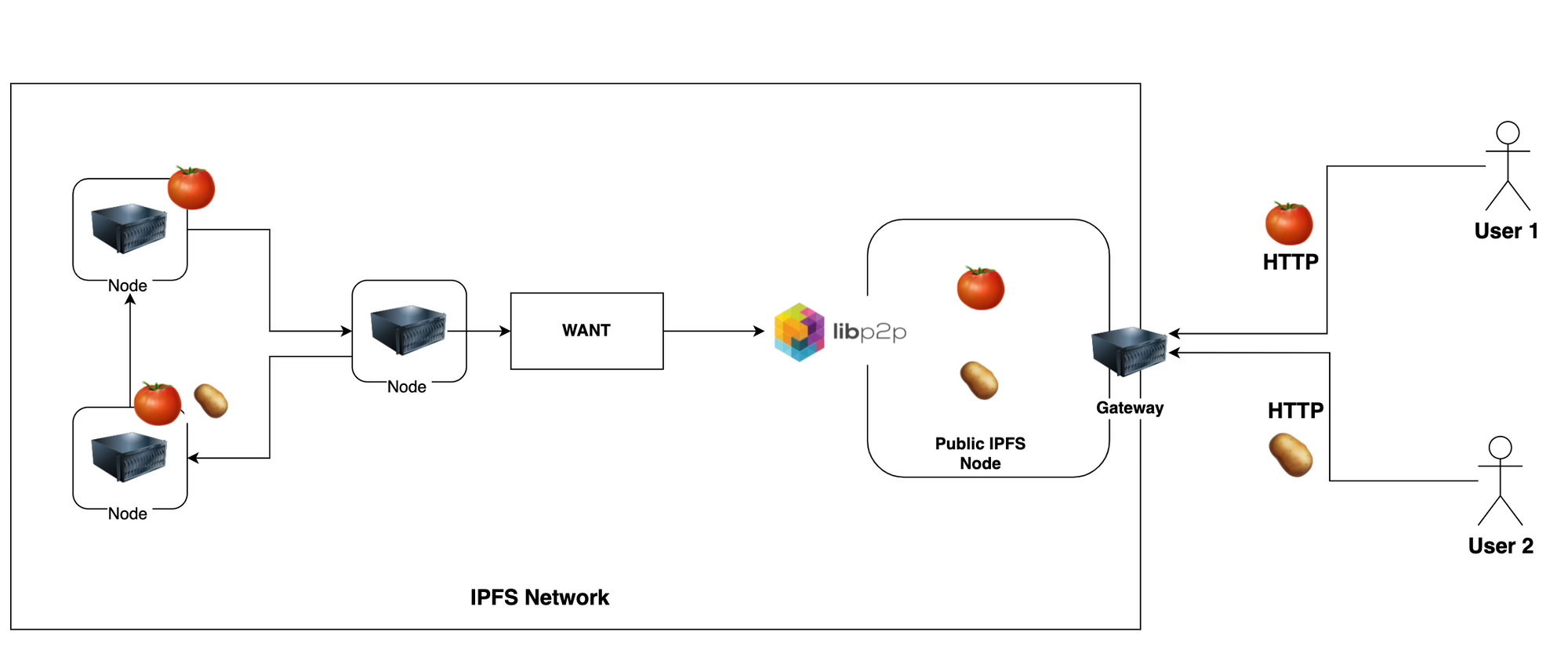
- A gateway is an HTTP interface to an IPFS node.
- On our gateway, we will allow any user to retrieve arbitrary content from IPFS Network.
- If a user asks for a 🍅 content, nodes with 🍅 will provide. and the same example goes for the 🥔.
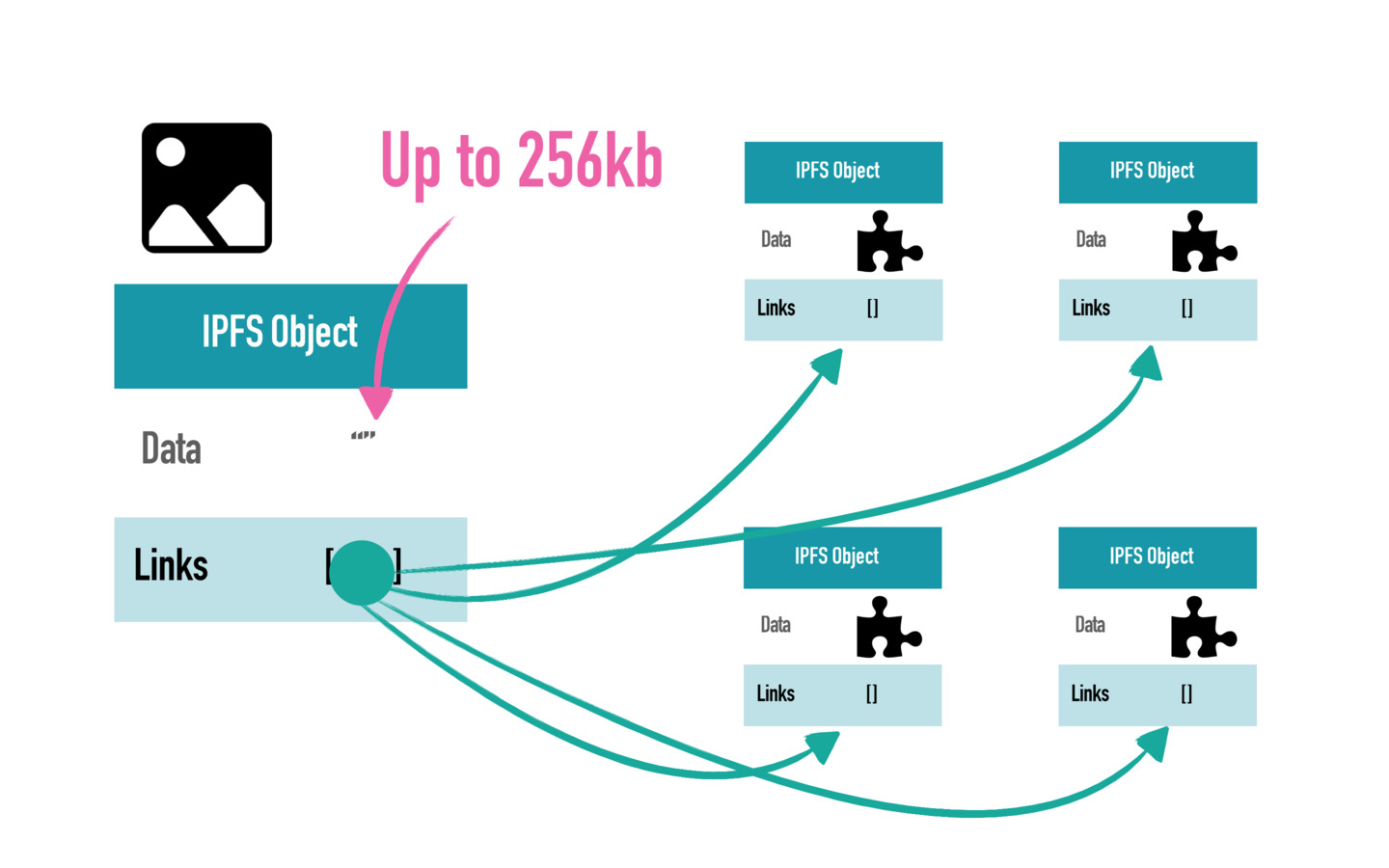
IPFS Objects
A Link structure has three data fields:
- Name — the name of the Link.
- Hash — the hash of the linked IPFS object.
- Size — the cumulative size of the linked IPFS object
IPFS objects are normally referred to by their Base58 encoded hash.
Exemple: IPFS object with hash QmeKsf9PmpH4LaJYG3fcBqddjCckuEFC8LHs67Wrg59d51
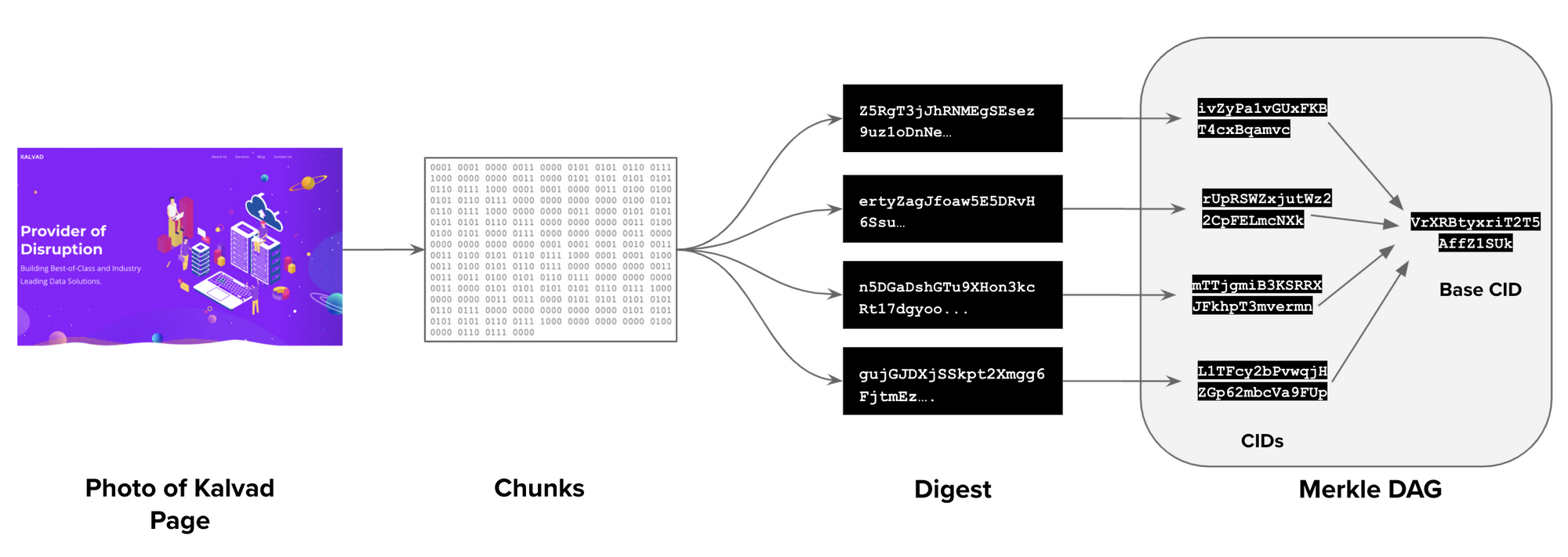
What is happening?
As we can see in the following picture, Our Kalvad photo will be converted into a binary file, then using IPFS technology this binary file will be split into different chunks.
Each chunk has its own Hash called CID(Content Identifier), grouped by a Base CID.
Let's get our hands dirty, Installation steps :
All installation instructions are available here: https://docs.ipfs.io/install/command-line/#official-distributions
wget https://dist.ipfs.io/go-ipfs/v0.10.0/go-ipfs_v0.10.0_linux-amd64.tar.gz
Unzip the file:
tar -xvzf go-ipfs_v0.10.0_linux-amd64.tar.gz
Move into the go-ipfs folder and run the install script:
cd go-ipfs
sudo bash install.sh
Test that IPFS has been installed correctly:
ipfs --version > ipfs version 0.10.0
Creating our first IPFS object
Let's introduce our folder :
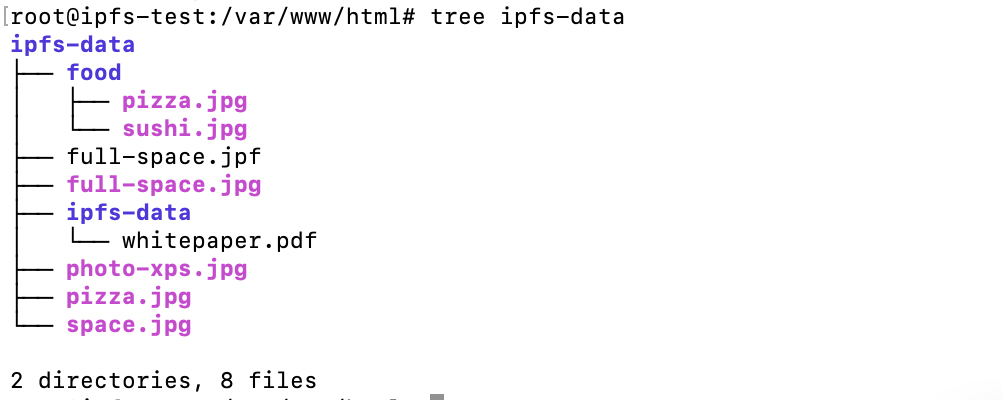
Where pizza.jpg is duplicated (inside food folder and in the ipfs-data folder
to add a folder into the IPFS network we have to run the following command:
ipfs add ipfs-data -r
The flag -r for recursive add, the result should looks like this :
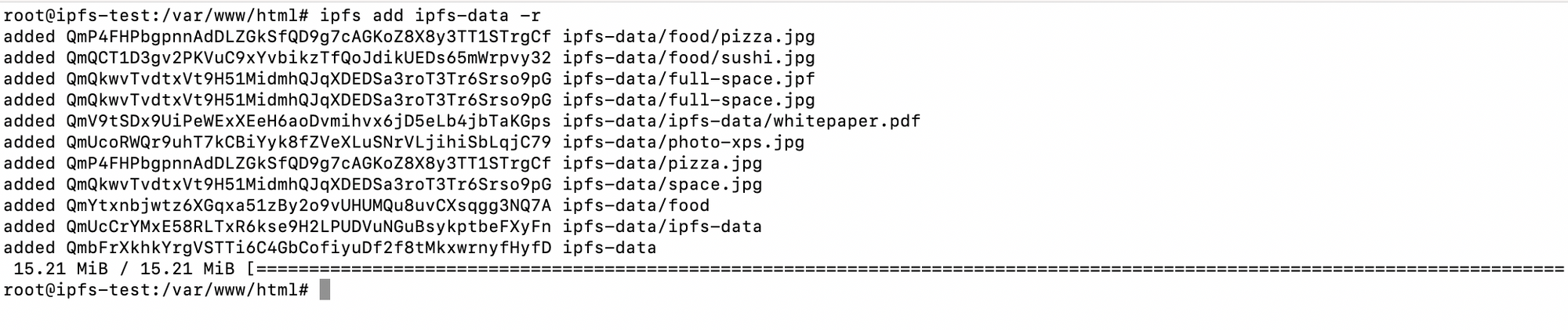
QmP4FHPbgpnnAdDLZGkSfQD9g7cAGKoZ8X8y3TT1STrgCf is the hash for ipfs-data/food/pizza.jpg.
We can see that both pizza.jpg files have the same hash, that's because we use content base addressing instead of Location-based, and since both pictures have the same content, they will have the same hash.
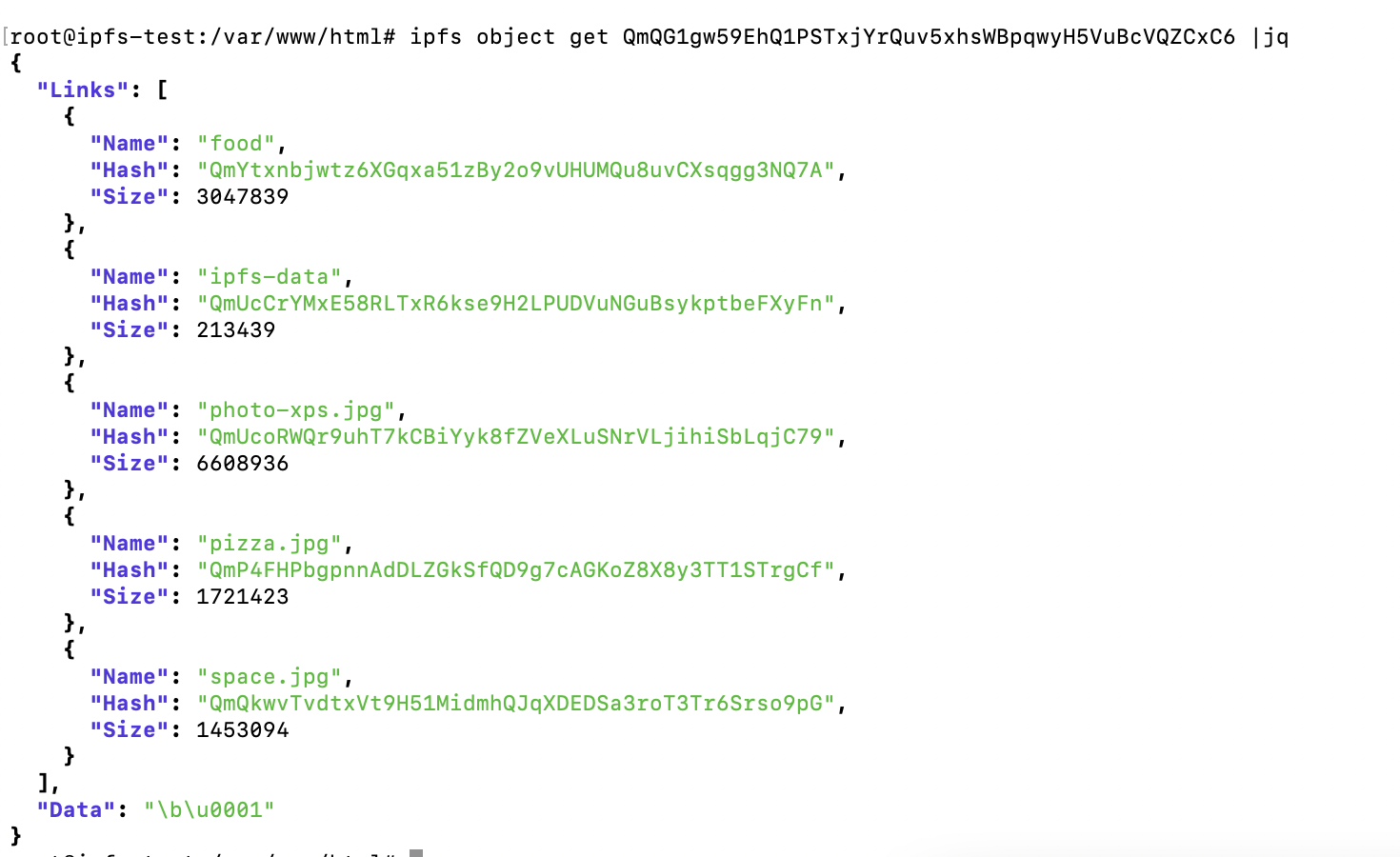
Let's get our IPFS object for the entire folder:
ipfs object get QmQG1gw59EhQ1PSTxjYrQuv5xhsWBpqwyH5VuBcVQZCxC6 |jq
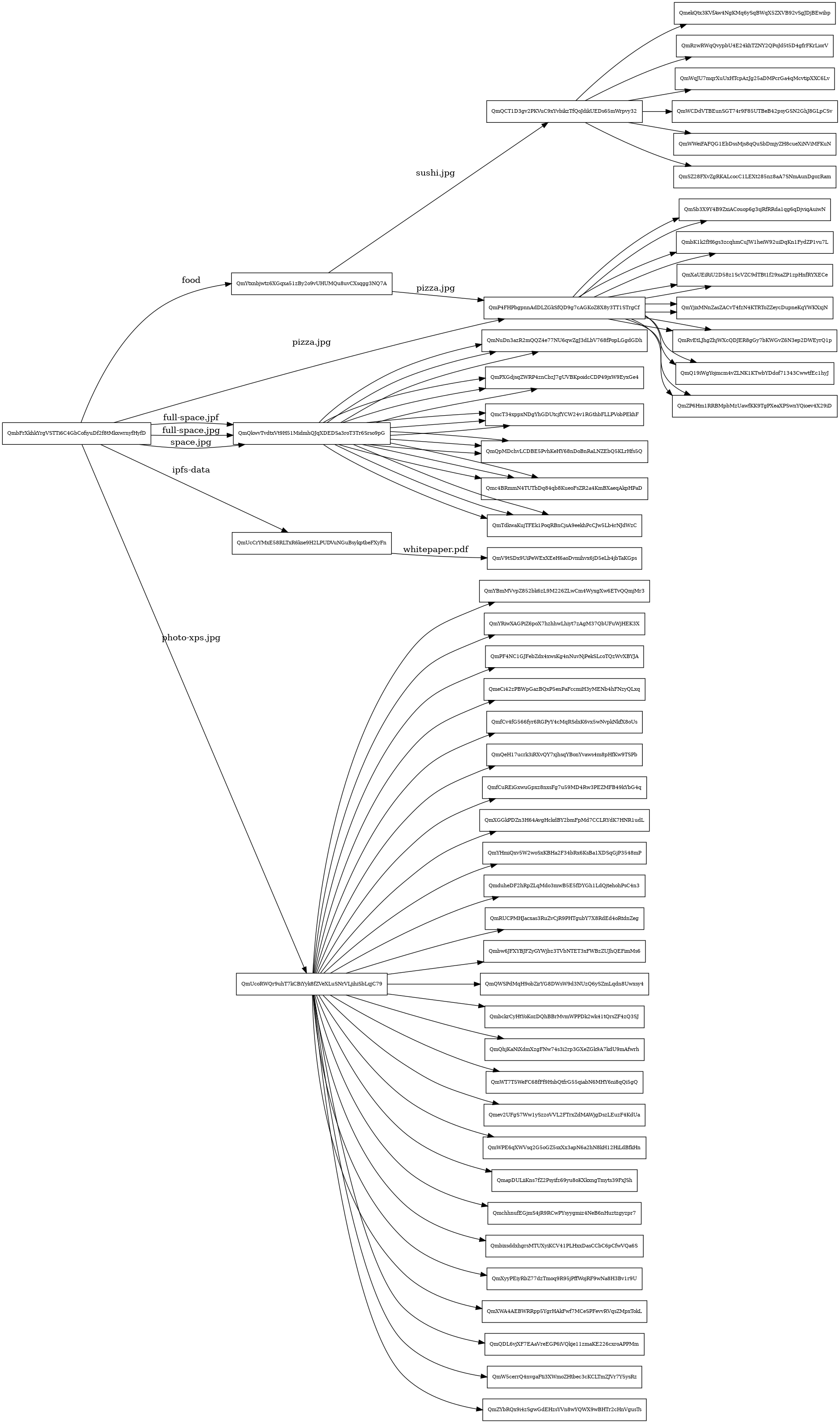
Let's see in-depth how our chunks are split and links between them, for that we will use graphmd.
graphmd QmbFrXkhkYrgVSTTi6C4GbCofiyuDf2f8tMkxwrnyfHyfD | dot -Tpng > tree.png
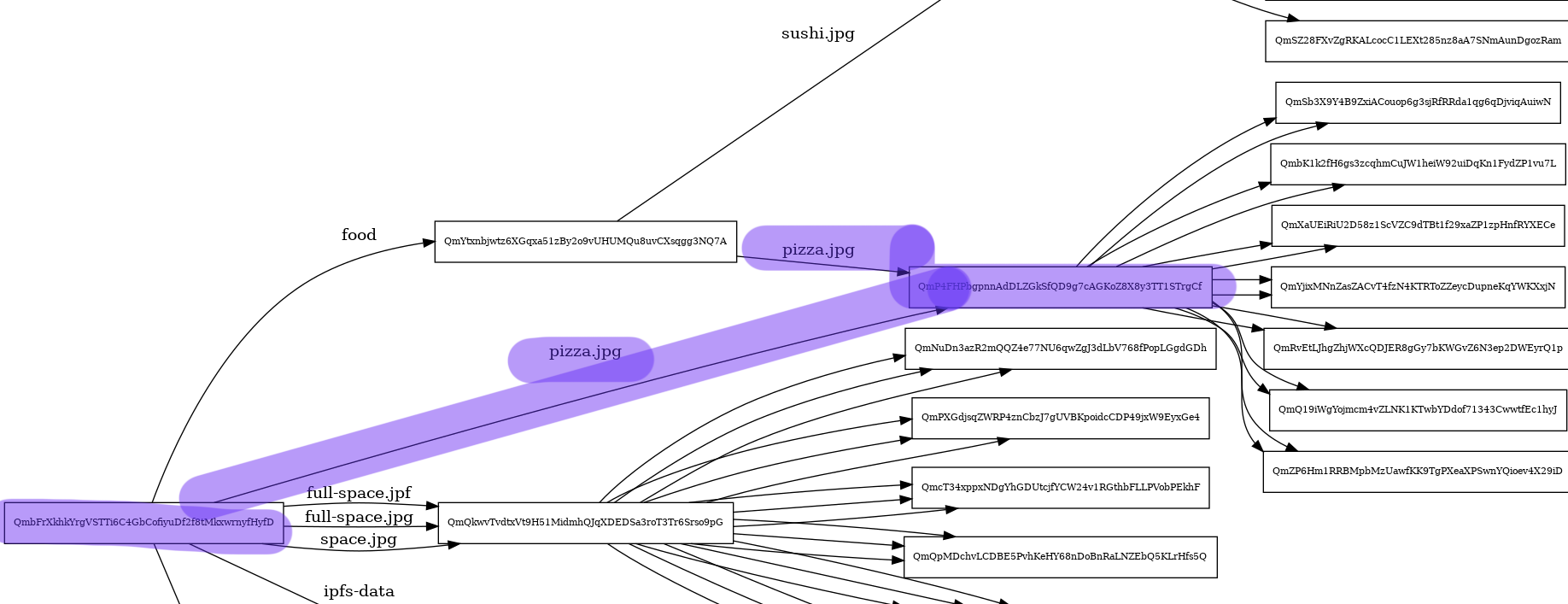
From the previous schema, we can see that both pizza.jpg files have links pointing to the same Hash, which confirms that they have the same content.
Now let's navigate and see our picture space.jpg which has the hash: QmQkwvTvdtxVt9H51MidmhQJqXDEDSa3roT3Tr6Srso9pG

ipfs object get QmQkwvTvdtxVt9H51MidmhQJqXDEDSa3roT3Tr6Srso9pG | jq
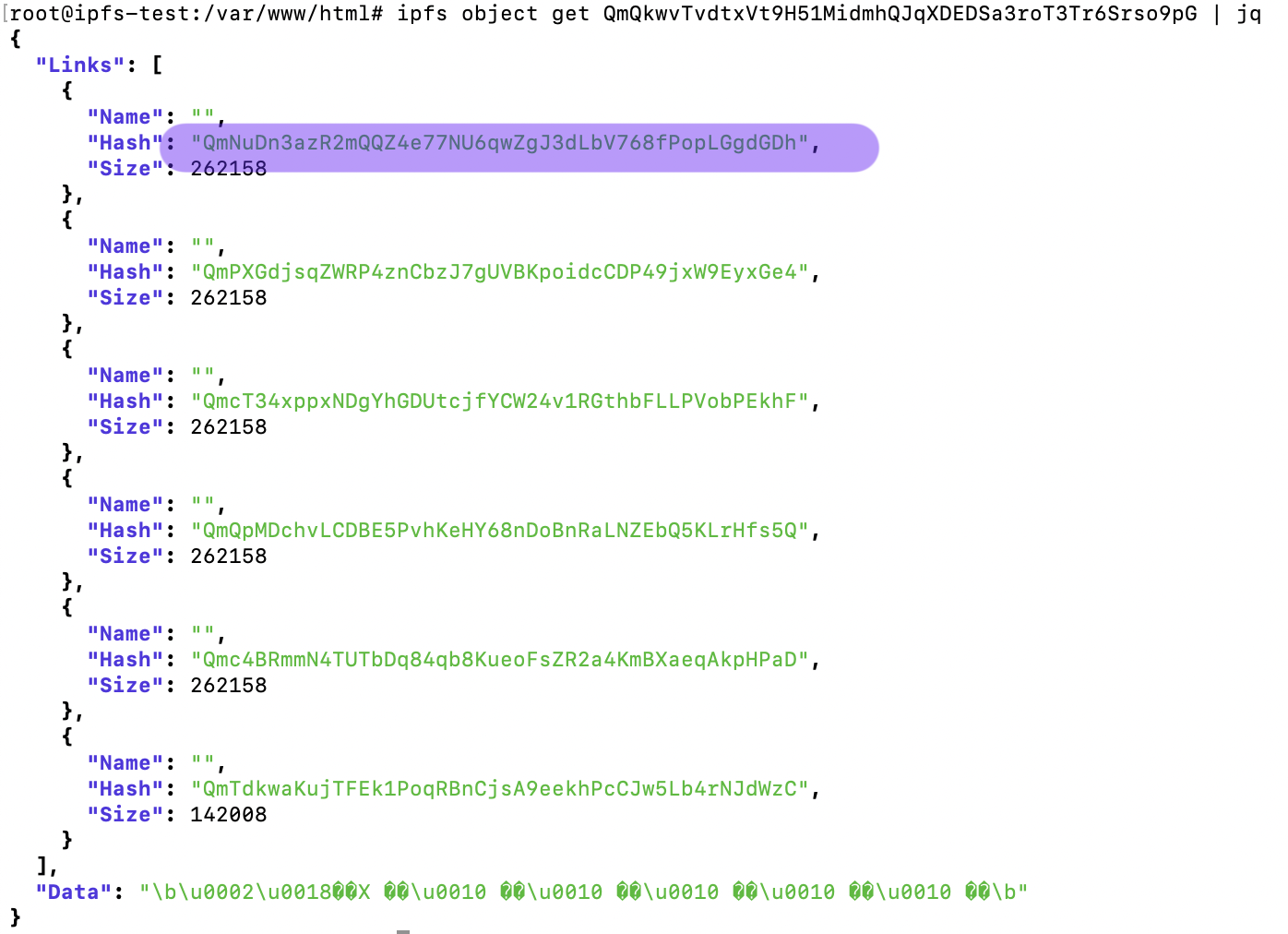
so space.jpg was split into 5 chunks of 256kb and 142kb in the 6th chunk.
Let's get only the first chunk with hash QmNuDn3azR2mQQZ4e77NU6qwZgJ3dLbV768fPopLGgdGDh using ipfs cat and save it into space-part1.jpg:
ipfs cat QmNuDn3azR2mQQZ4e77NU6qwZgJ3dLbV768fPopLGgdGDh > space-part1.jpg
when we visualize space-part1.jpg, we can see a small part of the image, and the rest is blank or void:

The IPFS Cluster

IPFS Cluster does not act as a traditional concept of the cluster because all IPFS peers are independent and the IPFS cluster software is syncing the data through a Consensus protocol.
IPFS Cluster provides data orchestration across a swarm of IPFS daemons by allocating, replicating, and tracking a global pin-set distributed among multiple peers.
IPFS Cluster uses a demon called ipfs-cluster-service that runs as an independent service that interacts with the IPFS daemon’s API.
Handle replication of millions of pins to hundreds of IPFS daemons in a fire&forget fashion: pin lifetime tracked asynchronously
Cluster peers take care of asking IPFS to pin CIDs at a sustainable rate and retry pinning in case of failures.
The cluster comes with a fully-featured API and CLI, ipfs-cluster-ctl provides a command-line client to the fully-featured Cluster HTTP REST API.
The cluster peers form a distributed network and maintain a global, replicated, and conflict-free list of pins.
The cluster also comes with built-in permissions, providing an embedded permission model that supports standard peers (with permissions to change the cluster pin-set) and follower peers (which store content as instructed but cannot modify the pin-set).
Note that every pin supports custom replication factors, names, and any other custom metadata.
What is Bitswap?
Bitswap is a core module of IPFS for exchanging blocks of data. It directs the requesting and sending of blocks to and from other peers in the network.

Bitswap is a message-based protocol where all messages contain want-lists or blocks. Bitswap has a Go implementation
Bitswap has two main jobs:
- Acquire blocks requested by the client from the network.
- Send blocks in its possession to other peers who want them.
Misunderstandings!
IPFS is not a place you upload to, it's a network you're a part of, meanwhile putting something into IPFS will magically make the Internet host the files forever.
IPFS is the permanent web: You shouldn't read "permanent" as "eternal", but as "not temporary", in the same sense as "permanent address" or "permanent employment".
HTTP is temporary in the sense that you're relying on a single server to actively continue serving a file for it to remain available. IPFS is permanent in the sense that, so long as the file exists somewhere in the network, it will remain available to everyone.#
IPFS is web 3.0 and will replace HTTP: The first being that no user would want to set up a full node. People on the IPFS network now are tech enthusiasts, however, no user will want to deal with hashes.
Hosting a website on IPFS: Hosting a website on IPFS using IPNS is simply terrible, and not user-friendly at all. Even all nodes pin my site, A CDN service such as Cloudflare would be way more effective and efficient.
IPFS for private data: Though of course there’s no reason you can’t store encrypted data on IPFS, encrypted data can’t be de-duplicated and it can’t be intelligently cached, because only its owner knows what it is.
The result is that accessing encrypted data on IPFS is not much more efficient than HTTP with some simple caching.
- Guaranteed availability
- Performance
- Security
Do peers tell what I have?
Peers who request content being advertised from a node can retrieve it and see that the node had that content.
- Every IPFS node on the network has a unique public identifier, known as a PeerID.
- Since PeerIDs are long-lived identities, it’s possible for someone to look up your PeerID in the distributed hash table (DHT) that stores public IPFS metadata.
- DHT contains metadata about the content that is requested or provided by PeerIDs,
Cost of the IPFS Cluster
Storage on the blockchain is extremely expensive.
Replication: We want to have a replication factor of 3, meaning at least 3 copies of each transaction on 3 distinct nodes.
We are going to use Scaleway as our cloud provider.
To provision a private IPFS Cluster for blockchain purposes, with 3 nodes we are going to need :
- 3 VMs as nodes
- Private Load balancer
- Public Load balancer


So the storage cost of 1TB will cost 99.25 EUR and 255 EUR for the infra monthly.
Security risks
Do not consume websites hosted on IPFS via path-based gateways, as this completely bypasses the same-origin policy.
Do not get misled by a shiny ✅ on the public IPFS gateway checker list.
The ✅ next to CORS means that the gateways wildcard allows all CORS access. This can be a security issue.

Be aware that public gateways may default to enabling CORS for all domains, allowing one CID to interact with resources from another CID (and potentially data stored for that CID).
You are trusting the gateway to deliver the content you requested. -> There is no way for your browser to verify whether the content received is what is stored in the IPFS distributed filesystem.
- You are trusting the gateway to not alter the CID before delivering it to you. Therefore, we can only recommend running a self-hosted gateway.
- The gateway may keep a protocol of your connection details and the data you have requested.
Major IPFS Users
- Cloudflare, runs a distributed web gateway to speed up and secure access to IPFS without the need for a local node.
- Microsoft ION, The digital identity system is built on Bitcoin and IPFS and its objective is to build a technology that allows creating a secure and scalable digital identity system at a global level.
- Brave, the search engine uses Origin Protocol and IPFS to host its decentralized merchandise store.
- Opera para Android has default support for IPFS, allowing mobile users to navigate ipfs: // links to access data on the IPFS network.
- Wikipedia use IPFS They have developed a mirror of their website, which allows them to access Wikipedia from jurisdictions where it is censored.
- Filecoin, uses IPFS to create a cooperative storage cloud based on IPFS.
Deploying Kalvad's Website on IPFS Network
ipfs add -r ./sample_website added QmaYZE5QQVR3TqQSL5WDcwuxUwBqczbMkmbHeoeNEAumbe sample_website/index.cssadded Qme5TzVW4en8HWP49N9nLHwUkAMhCn6zvWteoknmFDhwJg sample_website/index.htmladded QmThzr7LgYmUz6tfTArJK5tbrtidXSA12ZCL4ESy6HB8P2 sample_website/index.jsadded QmSYDncaMte6GPx5jC7kqeXWnrKsCp4nkLfQXPxiAKtECU sample_website/something.htmladded QmQ6HiGM7ikKgdyVuzfL7VukzaMCyxtNRnsnPu4nTPG9X3 sample_website 1.01 KiB / 1.01 KiB [=================================================] 100.00%
The hash printed in the last line is the CID for the whole directory and thus our website. We can see the sample website hosted on
https://ipfs.io/ipfs/QmUCF47VHN8PfUVjYfeL2MWUaeKN2twrQSfi8i4Shcu8dz
We have already done it, please find Kalvad's website in the IPFS network :
https://ipfs.io/ipfs/QmUCF47VHN8PfUVjYfeL2MWUaeKN2twrQSfi8i4Shcu8dz
Conclusion
In this post, We covered what IPFS is, how it works, and what was the reason behind its creation, and at what cost.
Whether you are a fan of IPFS or not, it's is an ambitious vision of a new decentralized Internet infrastructure, where it can be used in many different areas such as Blockchain.
If you have a problem and no one else can help. Maybe you can hire the Kalvad-Team.