You are software engineers, so COMPILE YOUR SOFTWARE
Why prebuilt Docker images leave performance on the table, and what happens when you compile Redis yourself and benchmark it properly with Warp10 and Celery.


Few weeks ago, I did a conference about Kubernetes/Docker (in French, sorry, but the slides are here), and I put inside a statement that some people, rightfully, were holding me accountable for: Docker images are slow because they are using old technologies!
But Loïc, what the hell is this scale? You are supposed to be a scientist, and you give us this poop?
I was saying that if you compile yourself your software (inside a container or not) you are going to have big improvements. But people didn't believe me.

So in order to prove them wrong, as my ego was really in pain, I decided to give a shot to a proper test scenario, based on the compilation of Redis.
Why Redis?
One of the most used software where performance has a huge impact is Redis. It's widely used in the industry, mostly as cache, or fast KV in-memory storage. You can clearly imagine the performance impact of this kind of system.
So we did what we do usually (and what a lot of people should do), we had a look on the doc. What did we found? redis-benchmark.
redis-benchmarkabPerfect, the benchmark software is included inside the software, nice!
Infrastructure
We wanted a reliable and cheap infrastructure to test our system. As usual, we chose Scaleway.
In order to perform the test properly, we needed to have the following servers:
- Some servers to execute the test
- One server to gather results
Test Executor

We choose a DEV1-L. The specifications are as follow:
- 4CPU (AMD EPYC 7281)
- 8GB Ram (ECC)
- 40GB Disk
But wait, Redis is mono-thread, why should we need 4 cores? Because the 4 cores are dispatched as:
- core 1: celery (more explanation coming after)
- core 2: redis
- core 3-4: redis-benchmark
Our base OS is something that we like to use in production Archlinux.
Our celery is configured to have a concurrency of 1, so no multiple tests running at the same time on the machine.
Results Gatherer
Our result server is a smaller server, with one of the most innovative data platform: Warp10.
Warp10 allows us to crunch numbers at a very high speed, with a low latency.
Tasks
The tasks are going to be dispatched through celery with the underlying usage of Kalvad's RabbitMQ cluster. Our interest for using this technology is:
- even if a task fail, the next one is going to pick up.
- we can add more servers that are going to take the celery messages.
The code of the task is available here. As you can see, we are launching redis-benchmark through a python subprocess, asking to have the output in CSV, then we parse it and push it on Warp10 as a result. Simple.
Except that it's not!
the command is as followed:
redis-benchmark -q -n <req> --csv -d 1000 --threads 2 -p <port>What are these parameters?
-n give the number of requests, all our tests were using 200,000 as value
-d 1000 is the data size of SET/GET value in bytes (default 2), we thought that 1kB was more realistic
-p is the port against which to test, and we did something great: We were running one redis per port (more details below)
Results from a Benchmark (example)
redis-benchmark -q -n 100000 --csv -d 1000 --threads 2 -p 6379
"test","rps","avg_latency_ms","min_latency_ms","p50_latency_ms","p95_latency_ms","p99_latency_ms","max_latency_ms"
"PING_INLINE","200000.00","0.157","0.032","0.143","0.271","0.359","0.623"
"PING_MBULK","199600.80","0.142","0.024","0.127","0.239","0.319","0.807"
"SET","200000.00","0.153","0.032","0.143","0.239","0.279","1.271"
"GET","199600.80","0.154","0.032","0.151","0.271","0.327","0.599"
"INCR","200000.00","0.159","0.032","0.151","0.255","0.303","0.519"
"LPUSH","199600.80","0.178","0.040","0.167","0.287","0.327","0.751"
"RPUSH","200000.00","0.169","0.040","0.159","0.239","0.319","0.559"
"LPOP","200000.00","0.184","0.032","0.167","0.303","0.359","1.079"
"RPOP","199203.20","0.182","0.040","0.175","0.295","0.359","1.439"
"SADD","200000.00","0.154","0.032","0.143","0.247","0.303","0.511"
"HSET","199600.80","0.134","0.032","0.143","0.199","0.279","0.519"
"SPOP","199600.80","0.144","0.032","0.143","0.239","0.287","1.103"
"ZADD","200000.00","0.163","0.032","0.151","0.255","0.303","0.567"
"ZPOPMIN","200000.00","0.155","0.032","0.143","0.247","0.287","0.535"
"LPUSH (needed to benchmark LRANGE)","199600.80","0.177","0.040","0.167","0.263","0.319","0.615"
"LRANGE_100 (first 100 elements)","30750.31","1.096","0.144","1.071","1.455","1.551","2.895"
"LRANGE_300 (first 300 elements)","11106.18","1.596","0.136","1.559","2.367","2.831","5.423"
"LRANGE_500 (first 500 elements)","6663.56","1.496","0.216","1.471","2.095","2.703","8.639"
"LRANGE_600 (first 600 elements)","5125.84","1.773","0.272","1.695","2.615","3.079","10.119"
"MSET (10 keys)","133333.33","0.257","0.056","0.223","0.351","0.407","2.359"
As you can see, we have 20 tests, with 7 metrics, which means that per test, we are going to produce 140 metrics.

Compilation time
In order to validate our concept, we chose to use multiple Redis 6.2.4 servers. Please note that the compiled servers should validate the redis setup by executing a make test, and they did
Redis Stock Arch
We just used the default redis inside the arch repository inside a container. The Redis Stock Arch is using:
- -O2 for compilation
- gcc 11.1.0 (April 27, 2021)
- jemalloc 5.2.1 (August 6, 2019)
- -march=x86-64 -mtune=generic
Redis docker latest
Same story, we just took the latest redis version available at the time of the test. It had the following settings:
- -O2 for compilation
- gcc 8.3.0 (February 22, 2019)
- jemalloc 5.1.0 (May 9, 2018)
- -march=x86-64 -mtune=generic
Redis docker Alpine
Same story than docker latest, except that we are taking the latest-alpine.
- -O2 for compilation
- gcc 10.3.1 (April 8, 2021)
- jemalloc 5.1.0 (May 9, 2018)
- -march=x86-64 -mtune=generic
Redis Optim by Kalvad - version #1
This one is the historic build from Kalvad, it's kind of a "naive" optimization
- -O3 for compilation
- gcc 11.1.0 (April 27, 2021)
- jemalloc 5.2.1 (August 6, 2019)
- -march=x86-64 -mtune=native
Redis Zig - For the Lulz
I saw an article few months ago, where a guy was using zig to compile some C code on ARM, and I loved the idea, so we wanted to include this setup in our test.
- -O3 for compilation
- zig 0.8.0, Clang 12.0.1 (July 8, 2021)
- jemalloc 5.2.1 (August 6, 2019)
- -march=x86-64 -mtune=native
Redis Mi by Kalvad aka super optim
This one is the historic build from Kalvad, but instead of using jemalloc we are using the mimalloc project.
- -O3 for compilation
- gcc 11.1.0 (April 27, 2021)
- mimalloc 2.0.2 (June 18, 2021)
- -march=x86-64 -mtune=native
Ports
Like I said, one port per server:
- 6379: stock arch
- 16379: mi malloc
- 26379: optim v1
- 36379: zig
- 46379: docker-latest
- 56379: docker-alpine-latest
Results

You can find a link to some raw results here.
The complete gts is available here, so you can import your raw results inside your own Warp10 instance.
But long story short, here are the final results:
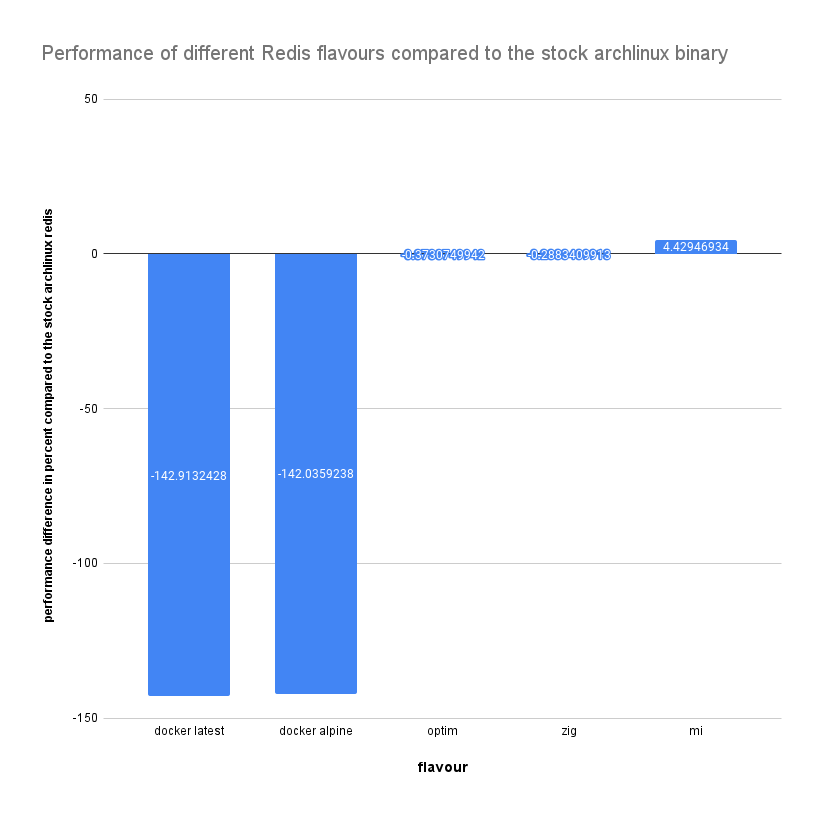
Optim flavour
The optim flavour was overall 0.37% slower than the stock arch, but why?
First of all, Redis is massively using memory, and the fact that we use the same version of jemalloc is reducing the impact. Second is the CPU. The AMD EPYC 7281 was released in Q4 2017, which is old. It does not have the full instruction set that could have more improvments .
Zig Flavor
The zig flavor was here as a joke, but it turns out it's a good one: Zig compile Redis is 0.288% slower than the stock arch! Good job Zig!
Docker Latest & Docker Alpine Latest
I think it's self explanatory, isn't it?
Whatever the packaging technology that you use, when you start to use 4 years old libraries with a software compiled for the entire earth, you have this kind of results: 142.92% slower.
Redis Mi by Kalvad aka super optim
The surprise: our previous tests were showing a far better improvement, so this result is kind of a disappointment for us.

We are still 4.42% faster than the stock arch, but why only 4.42%?
Simple. For the same reason than the optim flavour was not so different: the CPU.
We did some tests with a AMD EPYC 7282 (released in Q4 2019) and we saw bigger improvements.
Conclusion
It's a rule that we apply at Kalvad, and we know that some people that we respect a lot are doing the same (hello CleverCloud).
COMPILE YOUR SOFTWARES.
It's going to help you understand it, make your app faster, more secure (by removing the mail gateway of NGiNX for example), and it will show you which softwares are easily maintanable and reliable.
If you have a problem and no one else can help. Maybe you can hire the Kalvad-Team.
Stop Shipping Generic Binaries
We help teams squeeze real performance out of their infrastructure by building software for the hardware it actually runs on. From Redis and Warp10 to custom C and Zig services, we tune compilation, container images, and deployment pipelines for fintech, government, and high-throughput platforms where milliseconds count. Let's benchmark your stack.